


Intel Graphics Odyssey Pt. 1 – The AI GPGPU is a game changer


Originally published on September 27th 2020
When Intel announced it would launch its own GPUs, hiring former AMD graphics lead Raja Koduri in the process to head this ambitious endeavor, many wondered whether it was really possible for Intel to bring real innovation to the GPU market. Some reading this might not be aware that much of what we know today as a modern graphics workload has been developed and improved on for over more than half a century. Just as an example of this evolution process the first ray tracing algorithm was proposed by Arthur Appel – IBM Research – in 1968. Today, modern GPU architectures like Nvidia’s Turing or AMD’s RDNA are the result of decades of evolution in computer graphics that have resulted in the current state-of-art GPU pipeline. In fact, we might be tempted to paraphrase Philipp von Jolly’s infamous words to Max Planck and claim that:
“In this field, almost everything is already discovered, and all that remains is to fill a few holes.”
Philipp von Jolly
However, the progress in computer vision and machine learning has given rise to a new formidable paradigm that promises to provide a new level of visual perception far beyond what is feasible with modern computer graphics architectures today and which is redefining how we use graphics all together. Realizing the winds of change that are coming like a storm Intel Graphics have decided to lead the industry in its most ambitious odyssey: Bringing the next level of visual perception to the world through its innovative AI GPGPU architecture, based on neural rendering.


What is neural rendering?
Neural rendering is a new and revolutionary field of study that combines generative machine learning techniques with physical knowledge of computer graphics, which enables explicit or implicit control of scene properties such as illumination, camera parameters, geometry, etc. At this point it is very important that the reader understand the radical paradigm shift that neural rendering brings. In traditional computer graphics, the creation of a visual perception is based on physics and deterministic modeling scenes with the explicit reconstruction of these properties, which is computationally hard and extremely error prone. In neural rendering however, the creation of visual perception is based on statistical perspective, where a neural network learns from real world examples to generate new images. Thus, image quality depends mostly and relies on carefully-designed machine learning models, as well as on the quality of the training data used.

If you follow the enthusiast PC scene you might be aware that there is already a commercial application that partly implements this concept. Not too long ago Nvidia launched along with its Turing architecture their Deep Learning Super Sampling (DLSS) technology, the first commercial neural renderer, which through the tensor cores found in the Turing architecture executes an upsampling of the low-resolution rendered content with a neural network in real-time. As it is possible to observe – even in its current version 2.0 – the application of NVidia’s DLSS is not only quite limited in its functionality, but also completely preserves the entire conventional GPU pipeline. And this is where Intel’s disruptive concept comes in.
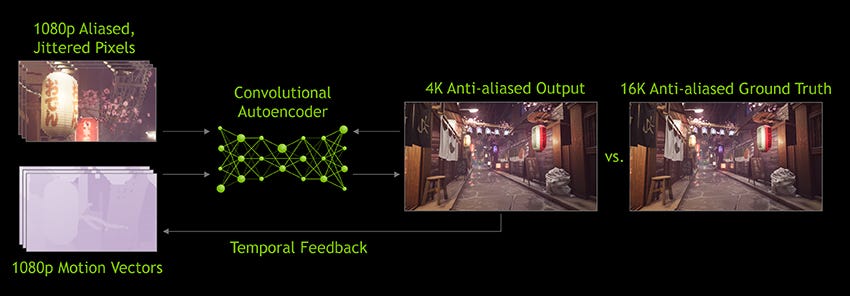
Graphics architecture including a neural network pipeline

Recently a new Intel patent was published that shows a series of new inventions in order to implement a complete AI GPGPU solution, which unlike NVidia’s DLSS, is totally independent of the traditional GPU pipeline. Such programmable graphic neural network pipeline includes several neural network hardware blocks such as AI tessellation, AI texture generation, an AI scheduler, an AI memory optimizer, and an AI visibility processor.
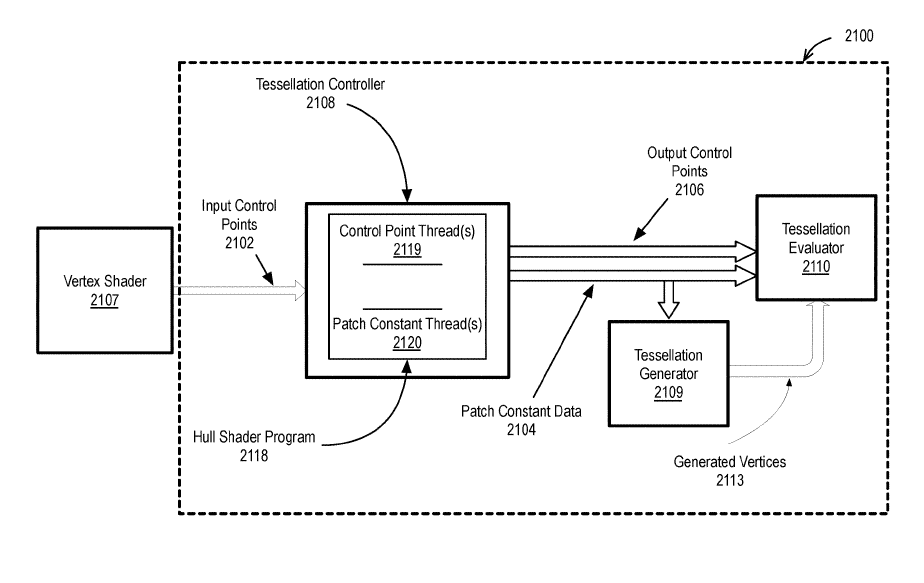

The AI-based tessellation mechanism proposed in the Intel patent can perform a higher-order geometry and tessellation inference using a neural network that is trained based on using a dataset that includes pre and post tessellated vertices, which can be used to replace the entire tessellation logic within a graphics pipeline with the output of the AI tessellation logic and the neural network pipeline flowing through the remaining programmable and fixed-function portion of the graphics pipeline. Also, the proposed tessellation mechanism can make use of a neural network to simulate tessellation of a 3D scene at the pixel level using a pre-trained neural network to simulate the look of a tessellated image without performing tessellation at the vertex or geometry level.



One of the most fundamental blocks that make up the series of inventions presented in the patent is the neural network block, which is addressable from a shader EU in the same way as a sampler and enables execution of a small neural network with a fixed maximum layer size and/or number of layers. This unit is programmatically configurable to accelerate neural network primitive operations, capable of performing a variety of operations to accelerate training or inference operations for a neural network, including matrix multiply and accumulate operations and/or operations to accelerate steps of a convolution operation. It is important to note that the patent itself describes the use of multiple layers in such a way that Intel can, through varying the numbers of single neural network block, develop different architectures for multiple applications (e.g. Low Power, High performance).

Also in the patent is described a method of geometry culling visibility using machine learning. The trained machine learning model can then generate visibility information on a per-object basis. In this process the machine learning model can determine whether an object is unobstructed, partially obstructed, or completely obstructed. This can avoid expensive pre-passes in fixed function logic within the graphics processor when performing geometry culling, further accelerating the pipeline execution.

The patent also provides a generative texture shader model based on generative adversarial networks in which a meta-shader can generate many different types of textures and is implemented using one or more variants of an EU’s addressable neural network blocks. The main advantage of this meta-shader system is that it can be configured to generate many different types of textures and can be used as a replacement for a procedural texture shader. So different terrain textures can be generated by this meta-shader system instead of having different procedural texture shaders for different types of terrain.

Lastly, the patent details an AI-Based Dynamic Scheduling system: A neural network hardware block that is responsible for programming the behavior of other hardware blocks to obtain the highest overall performance, which makes it responsible – as perfectly described in the patent – for the dynamic adjustment of scheduling blocks, memory controllers, caching hierarchy eviction algorithms, shared local memory banking, internal performance optimization hardware blocks, and power profiles. This unit is also responsible for four important tasks within this architecture:


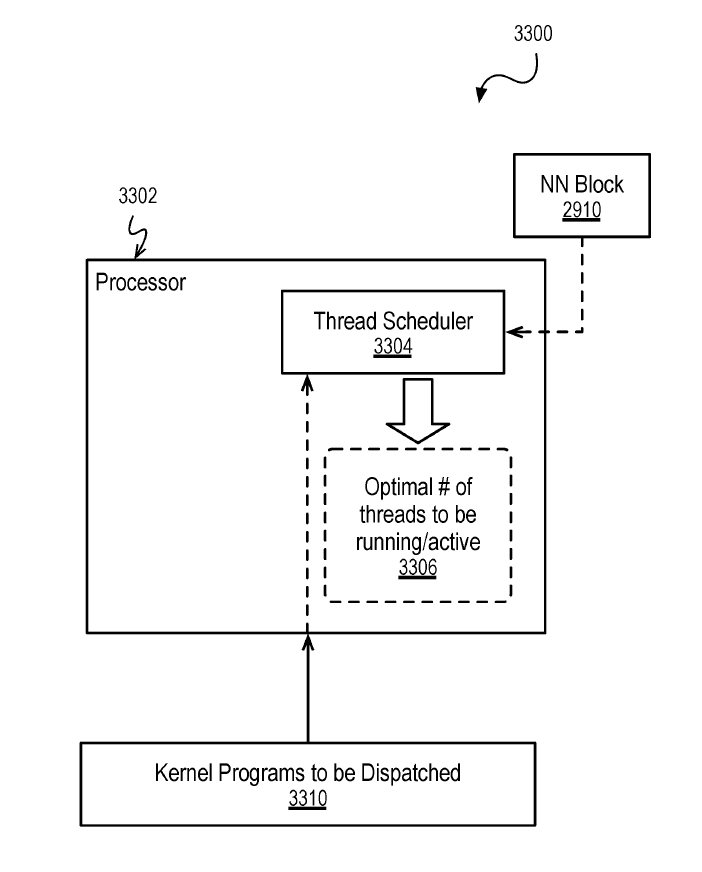

The Intelligent Memory Controller Scheduling: The memory controller is configured to work with an AI unit that can execute on a neural network block and be trained based on cache utilization, page faults, latency, power, execution unit wait time, or other factors to make better use of cache and achieve a reduction in latency associated with different types of requests.
Neural Network-Based Switching Between GPU Pipeline and a Neural Network Pipeline: Hardware logic responsible for switching between a traditional GPU pipeline and neural network-based image generation and processing pipeline, changing at run time depending on desired trade-offs between quality and performance.
AI Driven Thread Dispatch: The Neural Network blocks can be used to determine an optimal number of threads to be dispatched to the GPU through a trained neural network from data sets of workloads executed on the GPU. The neural network can be pre-trained and / or can be continuously trained to determine the optimal number of threads.
AI-Driven Hardware Memory Prefetching: This is AI-driven memory prefetching that is implemented via logic within the AI memory optimizer which is configured to train a neural network to learn memory access patterns for a variety of workloads and use the learned patterns to infer the memory access pattern for a given workload, resulting in improved prefetch efficiency of data from memory.
Intel Tensor Core architecture
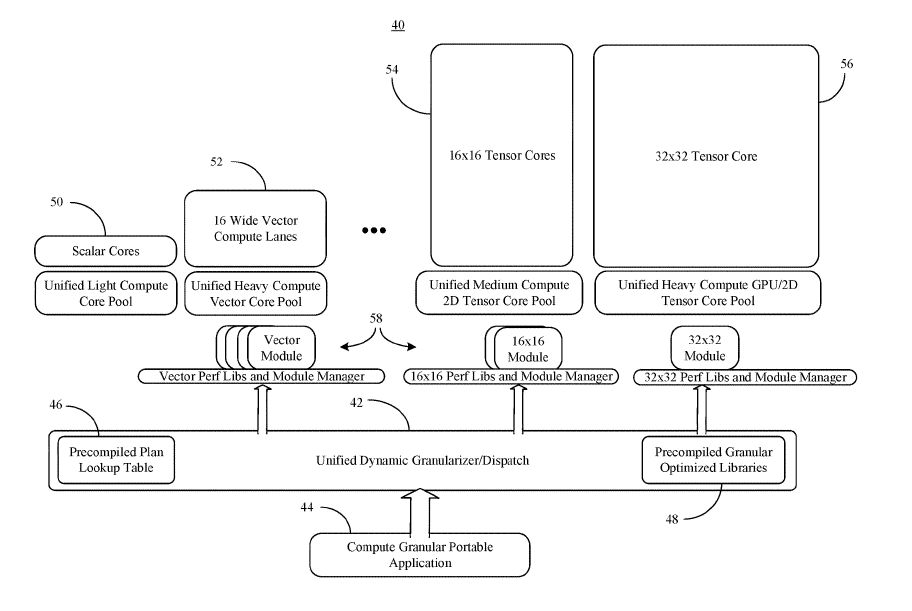
To complement this stunning new AI GPGPU architecture Intel also recently published a patent revealing its new heterogeneous tensor core architecture which enables matrix compute granularities to be changed on-the-fly and in real-time across a heterogeneous set of hardware resources. The method provided by Intel’s patent details a normalized tile execution solution that enhances performance by taking into account the runtime conditions when generating the partition configuration, leveraging knowledge about expected power consumption may enable the mapping of tensor operations to more power efficient core pools.

Therefore, at runtime, based on the detected tensor sizes and a list of available tensor cores, a table lookup might be performed by a runtime engine to retrieve the best/near optimal execution/partitioning plan along with any optimized intra-tensor-core optimized code generation.
The proposed unified dynamic dispatch for this heterogeneous tensor core architecture would allow a new level of granularization with its three levels of division, to the point of maximizing both the chip utilization and the AI acceleration to a level that goes far beyond that of Nvidia with its architecture of tensor cores features today, thus creating a true AI monster.
The path of evolution of visual perception in the post-Moore era
Based on all of this information we can confidently say that the current “brute force” method of generating improvements in visual perception through the conventional GPU pipeline has its days numbered. There are no more real optical node shrinking ahead and Dennard scaling has run its course. Most likely we will not see a mainstream Nvidia GPU with 100K+ CUDA cores to provide the full real-time ray tracing features in games running at native 4K. And even if such a GPU could be made it’s unlikely you have a nuclear power plant at home to be able to power your PC with such a device in it. There is no salvation here from traditional methods.
Intel is aware of the physical reality and is embarking on a real odyssey. Having to rewriting the way of working with graphics from scratch is an arduous task that needs a leadership capable of reinventing itself in the pursuit of innovation. And Raja Koduri has been leading Intel in this effort like a true silicon Ulysses. Such a patent from Intel is already the result of Raja’s efforts and his understanding of the need for a radical change in the way of working with graphics, views that are largely supported by many other members of the industry and academia. Intel is not alone in its graphical épopée.
Neural rendering is the only evolutionary path possible in this post-Moore era. It remains to be seen now if NVidia’s Jensen Huang will stop re-baking his old GPU architectures and make neural rendering actually “just work”.
Enjoyed this article and would like to see more?
Support Coreteks on Patreon 🙂
References and further reading:
A few holes to fill. Nature Phys 4, 257 (2008). https://doi.org/10.1038/nphys921
State of the Art on Neural Rendering. Tewari et al., Eurographics 2020, Arxiv (2020) https://arxiv.org/abs/2004.03805
Differentiable Rendering: A Survey. Kato et al., Arxiv (2020) https://arxiv.org/pdf/2006.12057.pdf
Neural Supersampling for Real-time Rendering, Lei Xiao, Salah Nouri, Matt Chapman, Alexander Fix, Douglas Lanman, And Antonkaplanyan, Facebook Reality Labs, SIGGRAPH 2020 – https://research.fb.com/wp-content/uploads/2020/06/Neural-Supersampling-for-Real-time-Rendering.pdf
US20200051309 – Graphics Architecture Including a Neural Network Pipeline, Labbre et al. – Intel Corporation (2020) https://www.freepatentsonline.com/20200051309.pdf
US20200133743 – Unified Programming Interface For Regrained Tile Execution, Baghsorkhi et al. – Intel Corporation (2020) https://www.freepatentsonline.com/20200133743.pdf
Deep Volumetric Ambient Occlusion, Dominik Engel and Timo Ropinski, EEE VIS SciVis 2020 – https://arxiv.org/pdf/2008.08345.pdf