


The Alder Lake hardware scheduler – A brief overview

Originally published on July 1st 2021

Over the last twenty years, the semiconductor industry has been experiencing a radical paradigm shift caused by the death of Dennard scaling and the rise of the dark silicon phenomenon, which forced each company to adopt several different strategies in order to continue to scale the computing power in the multiple computing platforms present in the world. A good example of this paradigm shift can be seen today in the development of processors that use heterogeneous multiprocessing aimed at embedded and mobile systems, where the cores share the same ISA but their micro-architectures offer different power / performance characteristics, enabling better match between application demand and computation capabilities, leading to substantially improved energy-efficiency.
However, when this approach is applied in desktop (or even server) environments, the power management and scheduling of a heterogeneous multicore processor proves to be truly challenging under a limited TDP budget when compared to a conventional homogeneous multiprocessor approach. The dramatically different power-performance between high and low performance cores implies the need to identify the right core for the right task at run time and migrate tasks accordingly. This dynamic task swapping within a heterogeneous multiprocessor without a fine-grained feedback control capable to dynamically estimating processors performance and energy efficiency capabilities often prevents the operating system scheduler from making the best scheduling decisions, leading to sudden changes in the operation of the system and brutally degrading the quality of user experience.
Pursuing a solution to this asymmetric nightmare, Intel has working to achieve all the benefits of this architectural approach in such way to ensure a seamless transition for both users and programmers. To this end, Intel has developed a new hardware guided scheduler interface which is the heart of the new Alder Lake processors and that has the potential to be a game changer against the multiple threats to its x86 dominance in this post-Dennard era.
The Intel hardware-guided scheduling interface
Recently, a new Intel patent was published revealing the details of implementing a closed-loop control method of resource allocation based on the current state of heterogeneous hardware blocks, in addition to a hardware-guided scheduling interface, which dynamically provides the communication of processor capabilities to the operating system based on power/thermal constraints of the different cores.

The main objective of the proposed method is to identify the most performance-sensitive thread and schedule it on the large core, leaving all other threads to be managed by the smaller cores. For this purpose, the evaluation process is divided into subdomains, each with its own specific criteria to determine the need for more resources for the proper execution of the task.
The first evaluation is whether there is need for more computing power. For this, some very specific metrics are used for this evaluation including expected thread run time, foreground vs. background activity, thread priority and other special cases, as in the example presented in the patent for a low latency profile associated with threads that need more system responsiveness. Once determined that there is no need for more computational power for proper execution, the thread is scheduled for the smaller core.
The second evaluation is to determine the thread dominance, that is, whether the thread is a single running thread or a single dominant thread of an overall workload. It is interesting to note that in these two possibilities the thread should be executed in the large core to improve the overall execution of the system. If so, the control system passes to the evaluation of power/thermal constraints. Otherwise, the thread is scheduled to a low power core. Once it is determined that there is no constraint, the last evaluation stage is invoked.


The last evaluation is to determine the performance scalability of the thread, based on the hardware feedback information provided by the hardware feedback circuit implemented within the power controller. If it is determined that the thread is scalable, the thread is finally scheduled for a large core. At this point, it is important for the reader to understand that there are certain situations where scheduling a thread for a small core can bring better overall performance than scheduling for a large core and some situations where scheduling a thread to a large core can result in better energy efficiency than a small core. Based on the performance scalability ratio which relates the workload power/performance scalability between larger and smaller cores, the number of active threads in the system and their relative energy-performance priority, the hardware scheduler is able to properly schedule threads for higher performance and/or improved power consumption, based on the hardware feedback information received. Finally, it is interesting to note that there is a direct relationship between the number of active threads and their relative energy-performance priority and the available power budget between different cores. Consequently, this will directly impact the choice of the type of core for the execution of the thread.
For a proper understanding of the hardware scheduler functionalities, it is now convenient to go deeper into the details of the hardware feedback interface structure and its behavior in the system.
The hardware feedback interface
The hardware feedback interface is a table stored in a dedicated location within a system memory, mapping into non-pageable writeback memory, which each core storage entry is associated with a given logical processor and store the performance and energy efficiency capability for the corresponding core. During the OS initialization, the OS allocates the hardware feedback interface memory region as a non-paged contiguous memory. Once enabled, the power controller generates hardware feedback information updates based on system workload and power and thermal constraints, which are updated in memory using a microcode technique.

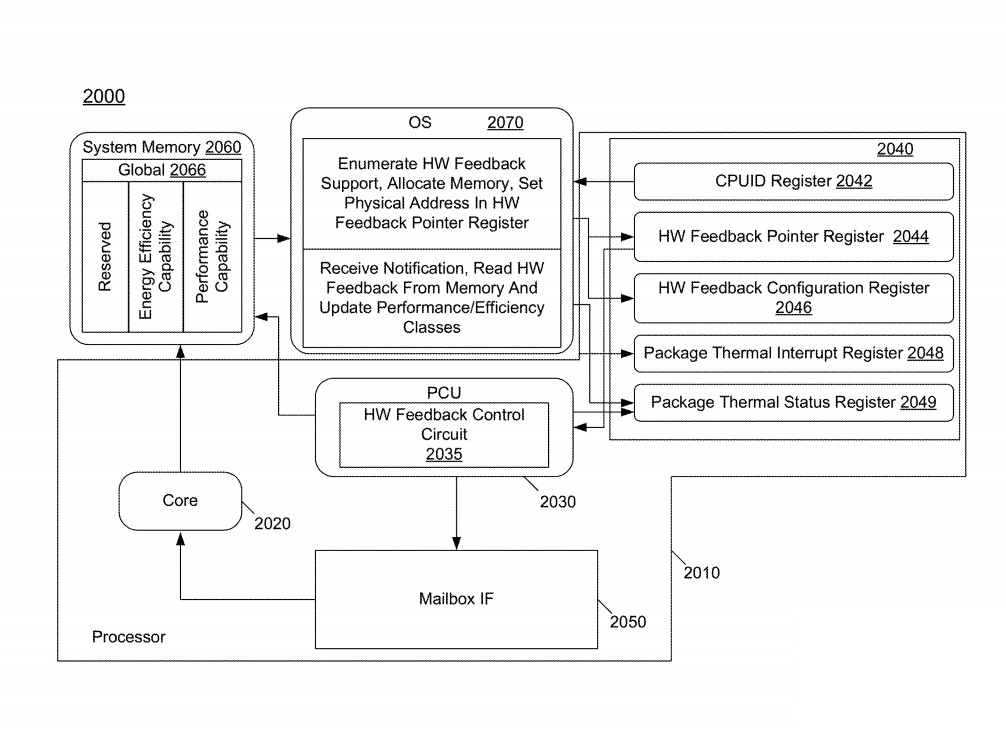
To control access to the hardware feedback interface memory, the patent shows the implementation of a notification log indicator, which will be set by hardware when a change to the hardware feedback information has occurred and been written to memory. This set indicator is to inform the operation system of an atomic update to the hardware feedback interface memory region, and that it will not be written to again until the operation system clears the indicator. To ensure overall system stability, the hardware feedback updates are controlled to occur no more than once per given interval and only when hardware feedback has meaningfully changed.
The resource allocation method step-by-step
The resource allocation method begins by receiving the current consumption information provided by the various current sensors across the multiple cores present in the processor, thus providing the power controller with accurate information about the level of current consumption within each of the cores or other processing circuits. Then, the power budget for the processor is calculated based on this current sensor information. In turn, this power consumption level is compared to the TDP level for which the processor is designed. From such information, a power headroom can be determined. The next step is to evaluate the power budget balance across four different processor domains (core domain, graphics domain, interconnect domain and the uncore domain), each of which needs to allocate a portion of the overall energy budget. After this evaluation, in the next step, the power controller is able scale the core domain power budget for different cores/core types based on one or more energy performance preference values, allocating appropriate independent budgets to heterogeneous cores of the processor.


The resource allocation method described in the patent utilize a lookup table-based technique to translate the total power budget into individual core budgets based on the power/performance differences between different core types. Therefore, the next step is to access the power-to-performance table to determine an operating point (voltage/frequency) for each of the different cores/core types. This operating point is a maximum performance point that each core type can support during a next execution cycle, which can be optimized or reduced to a lower level in light of physical constraints. It is important to note that this table provides a real indication of the architectural differences between cores. Therefore, even where different cores are associated with a common energy performance preference value, different operating points may be determined for the different cores/core types based on the information in this power-to-performance table.


In the next step, these operating points are processed into per core performance values and/or per core efficiency values, in such a way that the raw per core performance points are received as input and are interpreted into performance/efficiency measures. Finally, in the next step, it is determined whether the hardware state has occurred to one or more cores or core types that exceeds a threshold. If a hardware state change in such a way to exceeds a threshold is identified, the hardware feedback information will be reported to the operation system. Instead, if in the report to the operation system is indicated, the method concludes for the current evaluation interval and control passes back to begin, to start, to the next evaluation interval.

It is important that the reader understand that the transition point between different regions will be marked by efficiency and idling thresholds. In the performance region, a large core has high performance and is more power efficient than a small core for a given workload. In turn, in the reorder region, a small core becomes most efficient and a large core is less efficient. Finally, in an idling region, the small core is more efficient and the large core is idle. Thus, the last step track the transition of performance point of the cores from one region to another and update the status for hardware scheduler feedback.

To avoid frequent operation system updates, the patent describes that a hysteresis-based technique will be used in such way that bidirectional thresholds serve as a low pass filter, with different thresholds for transitions between two regions to remove frequent transients. Since hardware scheduler feedback is computed before performing the power budgeting, based in the energy performance preferences, this ensures that even if a thread is scheduled in/out by the operation system, the feedback will not change, thus providing the present power/thermal state of the system irrespective of the thread scheduled.
A future Intel behemoth in the horizon
With the information presented so far, I believe the reader has already understood the most basic concepts of Intel's hardware scheduler proposal, being able to understand the principles that try to ensure the robustness and reliability of the proposed solution, which Intel intends to deploy on its multiple platforms (including server). However, the reader is probably wondering what the next evolutionary steps might be and how far Intel intends to go. And, once again, another patent can give us a proper answer to this question.

Three years ago, an Intel patent was published, describing a workload dispatch interface to solve the problem of implementing heterogeneous acceleration solutions through dynamic migration of the threads between different types of processing elements of the heterogeneous multiprocessor, based on characteristics of a corresponding workload of the thread and/or processing elements.
Looking at the details of this patent, which will be duly presented in a future article, and knowing that the Alder Lake hardware scheduler patent presents within the hardware feedback interface structure a certain portion of the global area reserved for future capabilities, it is possible to conclude the possibility of the proposed hardware scheduler could serve as an power management infrastructure to creation a large-scale heterogeneous solution to directly compete against the AMD Exascale Heterogeneous Processor (EHP), which would include several accelerators, one of which already featured recently in an article [Link].

Over the last year, several Intel accelerators patents have emerged, showing that the possibility of developing an Intel heterogeneous behemoth is becoming more and more real. What it is possible to say today is that the hardware scheduler solution proposed for Alder Lake has solid foundations and a great future ahead. It remains to be seen how (and if) AMD will be able to respond to this accordingly.
Some references and reading recommendations:
US20210064426 - System, apparatus and method for providing hardware state feedback to an operating system in a heterogeneous processor – Gupta et al. – Intel [Link]
US20160132354 - Application scheduling in heterogeneous multiprocessor computing platforms – Iyer et al. – Intel [Link]
US20190347125 - Systems, methods, and apparatuses for heterogeneous computing – Sankaran et al. – Intel [Link]
Underfox – “Intel AI Photonic Accelerator” – Coreteks – 2021[Link]