
NVidia Ampere: A rushed response to what AMD is launching soon?


Originally published on May 20th 2020
Last weekend we finally got the long-awaited launch of the new Nvidia Ampere GPU architecture which is meant to replace Volta in the segments of Cloud, AI and HPC applications, adding new features aimed at improving both energy efficiency and better use of the resources present on the chip.

As very well detailed in the article presented by Nvidia on the new architecture, Ampere presents some significant changes in relation to Volta and new features aimed at improving the overall energy efficiency of the system. One of these new features is the new Multi-Instance GPU architecture (MIG), which allows the GPU to partition available computing resources into up to 7 instances for a significant improvement in the use of the resources present. A fundamental step towards the development of the foundations of a GPU architecture aimed at Exascale.

With this new feature, Nvidia will bring new unprecedented performance uplifts for their GPUs, allowing multiple programs to take advantage of existing resources in Ampere GPUs simultaneously and with a greater degree of freedom of resource allocation that no current AMD GPU can match. It is at this point that many readers may be asking: How can AMD respond to such an evolution provided by Nvidia? Is this the definitive end to the Radeon story? Is this Huang’s checkmate on Dr. Su?
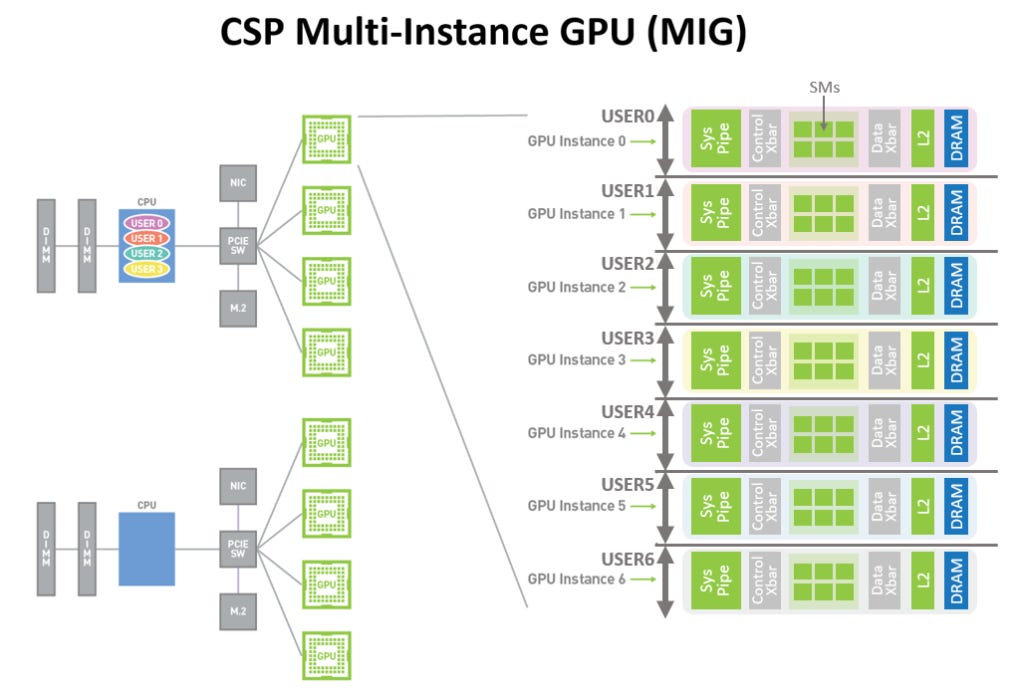
Well, this is where the real plot twist happens.
A few months ago, AMD published a new patent aimed at providing a multi-instance implementation in a more fine-grained way than that presented by Nvidia in the Ampere architecture. While in Ampere there is an explicit limit of resources that can be accessed by each instance, AMD’s proposal for multiple instances offers the opportunity for even more granularity in the allocation of available resources in such a way that, if an instance needs it, it can allocate for example more shader engines or more pixel engines to perform a given task dynamically for the multiple instances, thus enabling a complete use of the features present on the GPU, maximizing energy efficiency and utilization.
In addition, AMD’s patent allows the future AMD GPUs to support multiple concurrent queues, applications, draws, and dispatches from different guest OS’s. Each different workload is identified using a container ID to differentiate the workload from the other workloads. The container ID is created from a hash of the OS or virtual function ID in this implementation. This allows the GPU to support multiple concurrent queues, applications, draws, and dispatches from different guest OS’s.



This is just one example of what AMD has been preparing for its future generations of GPU based on RDNA / CDNA architectures. There are many more patents that could be cited along with everything we are seeing AMD bring with the new generation of consoles, to demonstrate that Ampere is actually an early (and necessary) response to what AMD is preparing to launch soon.
With Ampere’s presentation, I will now be able to research more in depth what Huang is preparing for what would become the “beyond Ampere” revenge. I hope to soon show you the results of my Nvidia patent searches.
Underfox is a Physicist, Telecom Engineering lover, HPC Enthusiast and Prog Rock/Metal fan. Underfox’s views are his own and do not necessarily reflect Coreteks’s. You can find Underfox on Twitter @Underfox3
References:
NVIDIA Ampere Architecture In-Depth, Krashinsky et al., Nvidia, 2020;
https://devblogs.nvidia.com/nvidia-ampere-architecture-in-depth/
AMD Patent: VMID as a GPU task container for virtualization – Fev. 6, 2020;
http://www.freepatentsonline.com/20200042348.pdf